So far you have accomplished:
- train two ML algorithms,
- create Django server with database models and REST API endpoints which will represent ML endpoints, models and requests.
What you will learn in this chapter:
- create ML code in the server,
- write ML algorithms registry,
- add ML algorithms to the server.
ML code in the server
In the [chapter 3][Build ML algorithms] we have created two ML algorithms (with Random Forest and Extra Trees). They were implemented in the Jupyter notebook. Now, we will write code on the server-side that will use previously trained algorithms. In this chapter we will include on server-side only the Random Forest algorithm (for simplicity).
In the directory backend/server/apps let’s create new directory ml to keep all ML related code and income_classifier directory to keep our income classifiers.
# please run in backend/server/apps
mkdir ml
mkdir ml/income_classifier
In income_classifier directory let’s add new file random_forest.py and empty file __init__.py.
In random_forest.py file we will implement the ML algorithm code.
# file backend/server/apps/ml/income_classifier/random_forest.py
import joblib
import pandas as pd
class RandomForestClassifier:
def __init__(self):
path_to_artifacts = "../../research/"
self.values_fill_missing = joblib.load(path_to_artifacts + "train_mode.joblib")
self.encoders = joblib.load(path_to_artifacts + "encoders.joblib")
self.model = joblib.load(path_to_artifacts + "random_forest.joblib")
def preprocessing(self, input_data):
# JSON to pandas DataFrame
input_data = pd.DataFrame(input_data, index=[0])
# fill missing values
input_data.fillna(self.values_fill_missing)
# convert categoricals
for column in [
"workclass",
"education",
"marital-status",
"occupation",
"relationship",
"race",
"sex",
"native-country",
]:
categorical_convert = self.encoders[column]
input_data[column] = categorical_convert.transform(input_data[column])
return input_data
def predict(self, input_data):
return self.model.predict_proba(input_data)
def postprocessing(self, input_data):
label = "<=50K"
if input_data[1] > 0.5:
label = ">50K"
return {"probability": input_data[1], "label": label, "status": "OK"}
def compute_prediction(self, input_data):
try:
input_data = self.preprocessing(input_data)
prediction = self.predict(input_data)[0] # only one sample
prediction = self.postprocessing(prediction)
except Exception as e:
return {"status": "Error", "message": str(e)}
return prediction
The RandomForestClassifier algorithm has five methods:
__init__- the constructor which loads preprocessing objects and Random Forest object (created with Jupyter notebook)preprocessing- the method which takes as input JSON data, converts it to Pandas DataFrame and apply pre-processingpredict- the method that calls ML for computing predictions on prepared data,postprocessing- the method that applies post-processing on prediction values,compute_prediction- the method that combines:preprocessing,predictandpostprocessingand returns JSON object with the response.
To enable our code in the Django we need to add ml app to INSTALLED_APPS in backend/server/server/settings.py:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
# apps
'apps.endpoints',
'apps.ml'
]
ML code tests
Let’s write a test case that will check if our Random Forest algorithm is working as expected. For testing, I will use one row from train data and check if the prediction is correct.
Please add two files into ml directory: empty __init__.py file and tests.py file with the following code:
from django.test import TestCase
from apps.ml.income_classifier.random_forest import RandomForestClassifier
class MLTests(TestCase):
def test_rf_algorithm(self):
input_data = {
"age": 37,
"workclass": "Private",
"fnlwgt": 34146,
"education": "HS-grad",
"education-num": 9,
"marital-status": "Married-civ-spouse",
"occupation": "Craft-repair",
"relationship": "Husband",
"race": "White",
"sex": "Male",
"capital-gain": 0,
"capital-loss": 0,
"hours-per-week": 68,
"native-country": "United-States"
}
my_alg = RandomForestClassifier()
response = my_alg.compute_prediction(input_data)
self.assertEqual('OK', response['status'])
self.assertTrue('label' in response)
self.assertEqual('<=50K', response['label'])
The above test is:
- constructing an input JSON data object,
- initializing ML algorithm,
- computing ML prediction and checking the prediction outcome.
To run Django tests run the following command:
# please run in backend/server directory
python manage.py test apps.ml.tests
You should see that 1 test was run.
System check identified no issues (0 silenced).
.
----------------------------------------------------------------------
Ran 1 test in 0.661s
OK
Algorithms registry
We have the ML code ready and tested. We need to connect it with the server code. For this, I will create the ML registry object, that will keep information about available algorithms and corresponding endpoints.
Let’s add registry.py file in the backend/server/apps/ml/ directory.
# file backend/server/apps/ml/registry.py
from apps.endpoints.models import Endpoint
from apps.endpoints.models import MLAlgorithm
from apps.endpoints.models import MLAlgorithmStatus
class MLRegistry:
def __init__(self):
self.endpoints = {}
def add_algorithm(self, endpoint_name, algorithm_object, algorithm_name,
algorithm_status, algorithm_version, owner,
algorithm_description, algorithm_code):
# get endpoint
endpoint, _ = Endpoint.objects.get_or_create(name=endpoint_name, owner=owner)
# get algorithm
database_object, algorithm_created = MLAlgorithm.objects.get_or_create(
name=algorithm_name,
description=algorithm_description,
code=algorithm_code,
version=algorithm_version,
owner=owner,
parent_endpoint=endpoint)
if algorithm_created:
status = MLAlgorithmStatus(status = algorithm_status,
created_by = owner,
parent_mlalgorithm = database_object,
active = True)
status.save()
# add to registry
self.endpoints[database_object.id] = algorithm_object
The registry keeps simple dict object with a mapping of algorithm id to algorithm object.
To check if the code is working as expected, we can add test case in the backend/server/apps/ml/tests.py file:
# add at the beginning of the file:
import inspect
from apps.ml.registry import MLRegistry
# ...
# the rest of the code
# ...
# add below method to MLTests class:
def test_registry(self):
registry = MLRegistry()
self.assertEqual(len(registry.endpoints), 0)
endpoint_name = "income_classifier"
algorithm_object = RandomForestClassifier()
algorithm_name = "random forest"
algorithm_status = "production"
algorithm_version = "0.0.1"
algorithm_owner = "Piotr"
algorithm_description = "Random Forest with simple pre- and post-processing"
algorithm_code = inspect.getsource(RandomForestClassifier)
# add to registry
registry.add_algorithm(endpoint_name, algorithm_object, algorithm_name,
algorithm_status, algorithm_version, algorithm_owner,
algorithm_description, algorithm_code)
# there should be one endpoint available
self.assertEqual(len(registry.endpoints), 1)
This simple test adds a ML algorithm to the registry. To run tests:
# please run in backend/server
python manage.py test apps.ml.tests
Tests output:
System check identified no issues (0 silenced).
..
----------------------------------------------------------------------
Ran 2 tests in 0.679s
OK
Add ML algorithms to the registry
The registry code is ready, we need to specify one place in the server code which will add ML algorithms to the registry when the server is starting. The best place to do it is backend/server/server/wsgi.py file. Please set the following code in the file:
# file backend/server/server/wsgi.py
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'server.settings')
application = get_wsgi_application()
# ML registry
import inspect
from apps.ml.registry import MLRegistry
from apps.ml.income_classifier.random_forest import RandomForestClassifier
try:
registry = MLRegistry() # create ML registry
# Random Forest classifier
rf = RandomForestClassifier()
# add to ML registry
registry.add_algorithm(endpoint_name="income_classifier",
algorithm_object=rf,
algorithm_name="random forest",
algorithm_status="production",
algorithm_version="0.0.1",
owner="Piotr",
algorithm_description="Random Forest with simple pre- and post-processing",
algorithm_code=inspect.getsource(RandomForestClassifier))
except Exception as e:
print("Exception while loading the algorithms to the registry,", str(e))
After starting the server with:
python manage.py runserver
you can check the endpoints and ML algorithms in the browser. At the URL: http://127.0.0.1:8000/api/v1/endpoints you can check endpoints, and at http://127.0.0.1:8000/api/v1/mlalgorithms you can check algorithms.
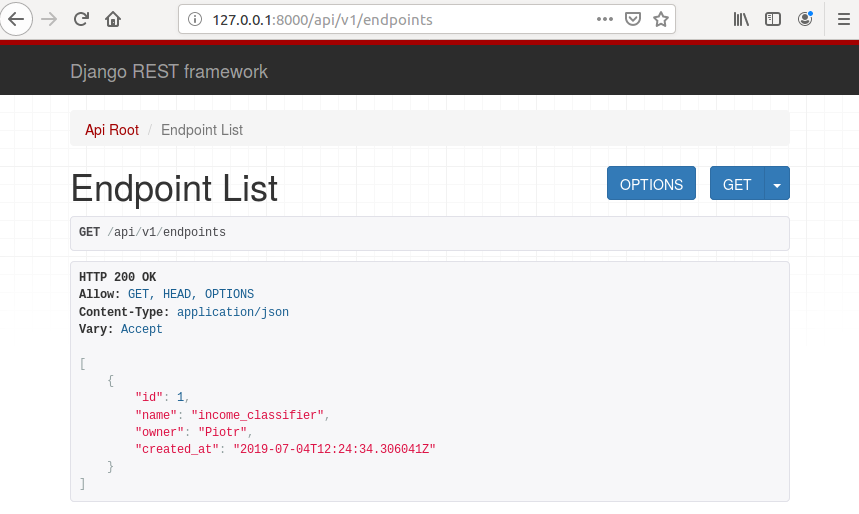
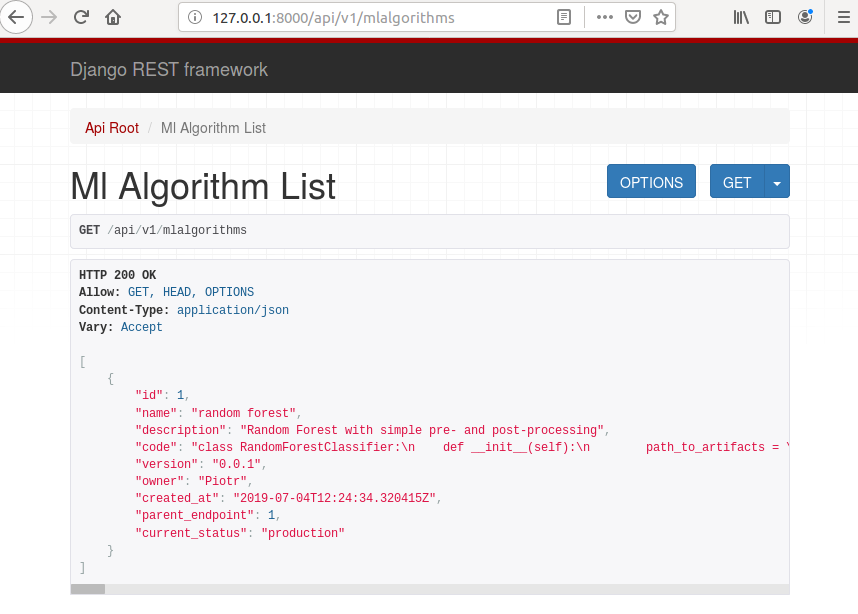
Add code to repository
We need to commit a new code to the repository.
# please run in backend/server directory
git add apps/ml/
git commit -am "add ml code"
git push
What’s next?
We have our ML algorithm in the database and we can access information about it with REST API, but how to do predictions? This will be the subject of the next chapter.